Bioinformatics
Processing and analyzing data generated with next-generation sequencing approaches can require extensive computational experience and computing power. RTL Genomics can help with many types of bioinformatic analyses.
Get Help With your Analyses

RTL Genomics has an experienced team of Ph.D. computer scientists and computational biologists ready to help push your project past the finish line. Whether you need assembly and annotation of genomes, analysis of transcriptomes, or help with custom pipelines, we have a solution that will meet your needs.

Krona Graph
For our most popular service, 16S barcode sequencing, please visit our Amplicon Bioinformatics Pipeline below to familiarize yourself with our data processing workflow.
RTLGenomics provides three zipped archive files: raw, fasta, and analysis files. Within the analysis file, there is an interactive Krona graph which displays taxonomic data from your samples.
Please visit our Sample Data page for Krona graph information and example data files.
Some of the services we offer are below:
Classification of specific marker-based microbial diversity assays other than 16S (e.g. 18S, ITS, chloroplast, mitochondria)
Classification of shotgun library-based metagenomic diversity analysis potentially to the strain level.
Genome assembly and annotation.
RNASeq and expression analysis
For more information on our standard bioinformatics policies or to get information about having analyses done, please see our Bioinformatics FAQ or contact us.
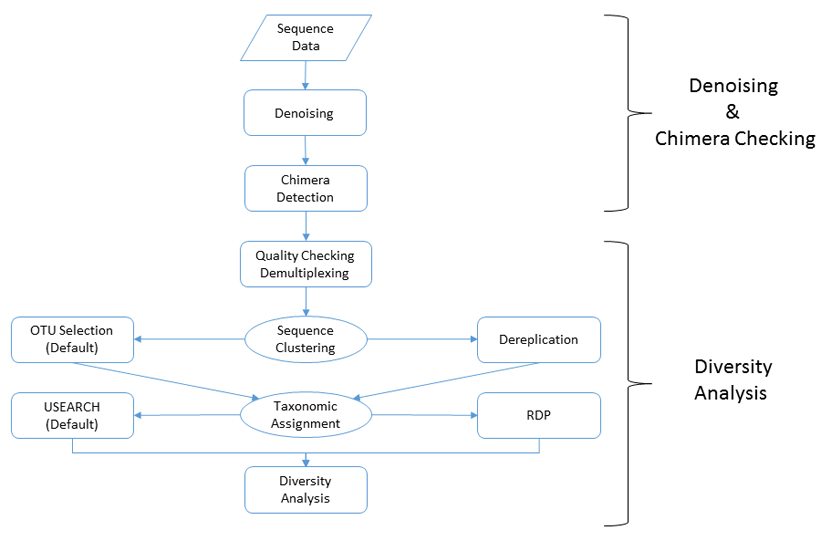
Amplicon Bioinformatics Pipeline
Our microbial diversity services include taxonomic analysis using our custom data analysis pipeline. The data analysis pipeline consists of two major stages, the denoising and chimera detection stage and the microbial diversity analysis stage, which are further broken up as follows:
Denoising and Chimera Checking
1. Quality Trimming
2. Denoising
3. Chimera Checking
Microbial Diversity Analysis
1. Quality Checking
2. FASTA Formatted Sequence/Quality File Generation
3. Sequence Clustering
4. Taxonomic Identification
5. Data Analysis
For an in-depth description of our pipeline methodology, please visit our Data Methodology.